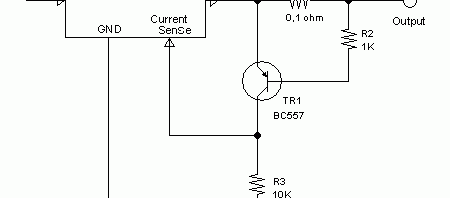
Converting 5V 7805 Linear Voltage Regulator to Produce 6.4V Output
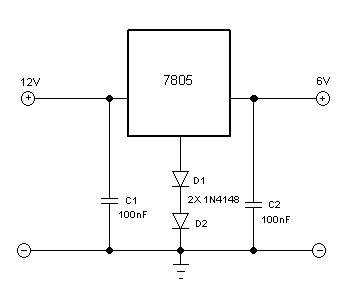
Making a linear voltage regulator using 78XX integrated circuit series is very easy, it needs only one or two additional components to make the integrated circuit chip works. The problem arises when we need a custom voltage specs for the output, since they come in discrete fixed voltage variation (specified by XX parameter printed in the body of the IC […]
Read more